.png)

Obtain the relationships between authors and reputation during runtime from various repositories such as Wipo, DBLP, PubMed, ArXiv, Twitter, DBpedia, Yago!
The Bibliographic Search case study focuses on exploiting information from various data sources (e.g. Cordis, Wipo, DBLP, PubMed, ArXiv, Twitter, DBpedia, Yago).
Bibliographic search is an important aspect of research and technology development worldwide. Its proper use allows companies and researchers to know about the originality and relations of their work with the work of other researchers by means of searching bibliographic and patent repositories such as EPO Patstat, Scopus or Medline. However, it is restricted nowadays to mere keyword search queries launched over one of those huge repositories at a time, with answers being ranked lists of papers. This situation is very limiting because of the huge amount of time and intellect that scientists must spend doing repeated search on different data sources. Also, the complexity and exploitation of relations among the metadata involved in bibliographic repositories (e.g. keywords, authors, papers, citations, and publication venues) are not fully taken into account by the information management technology. Information retrieval systems, on one hand, typically only consider the text in the document, and do not exploit the context. They do not follow the relationships among the metadata fields of the bibliographic items in order to provide customized results, nor continue the exploration of the presented results based on the relations of the metadata fields, or suggest documents/conferences/authorities/etc. based on the user’s interest. On the other hand, relational technology allows for a multidimensional view of the metadata, but it performs deficiently on exploration queries.
In a real scenario of bibliographic and patent data analysis, data is split into multiple repositories based on different technologies. For example, the full text of papers or patents is stored in documental databases; bibliographic metadata is represented in the form of properties in a key-value storage or in a column-store; personal and organization information is stored in a relational database management system; and, finally, the relationships between researchers, organizations, groups and areas of interest are represented as a complex network inside a graph database management system.
In this context it is very useful to use the CoherentPaaS technology to solve queries such as “which are the related papers for an specific european project?” or “who are the most appropriate reviewers for a european project?”. These queries can be solved using a single JDBC statement and the technology is able to integrate the results and provide a single result set. Let’s see the execution plan that solves the potential reviewers.
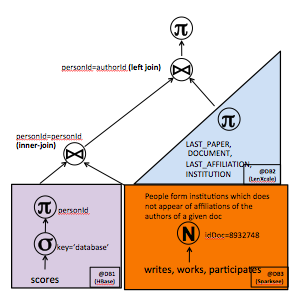
reviewers-query
Specifically, this execution plan shows a query that needs to integrate results from 3 different datastores: Sparksee, LeanXcale and Eutropia.
Moreover, the update process of the data is incrementally and the holistic transaction manager is the responsable to update the databases under the same transaction. Otherwise, it would become very error prone because the developer needs to deal with the data consistency issues.
On top of a cluster of bibliographic data repositories interrelated through the relationships graph, researchers run queries that extract and integrate information from more than one source. A query example is literature review, where a scientist has been asked to start the research for a new line of products in the company she works, or to search for literature (both patent and non-patent) that could invalidate the novelty of the invention claimed by a given patent or patent application. In this case, documental databases are searched to find similar papers or patents, where the graph database relates the documents found by the keywords, the authors or the involved organizations. Another example is reviewer or expert search, where a program committee chair of a conference is searching for good reviewers for a paper submitted. First, similar papers are going to be found by document similarity or by areas of interest extracted from the graph database. Then, the authors are ranked by using the bibliographic metadata associated to their papers. Finally, the final candidates for reviewers are filtered by the conflicts of interest stored into the graph database.


